この記事では、「正規分布」とは何かをわかりやすく解説します。
正規分布表の見方や計算問題の解き方も説明しますので、ぜひこの記事を通してマスターしてくださいね!
目次
正規分布とは?
正規分布とは、代表的な連続型確率分布の \(1\) つで、期待値(平均)を中心として左右対称に広がる確率分布です。
自然界や世の中のさまざまな現象に当てはまる分布であることから、その名前「正規分布 (normal distribution)」がついています。
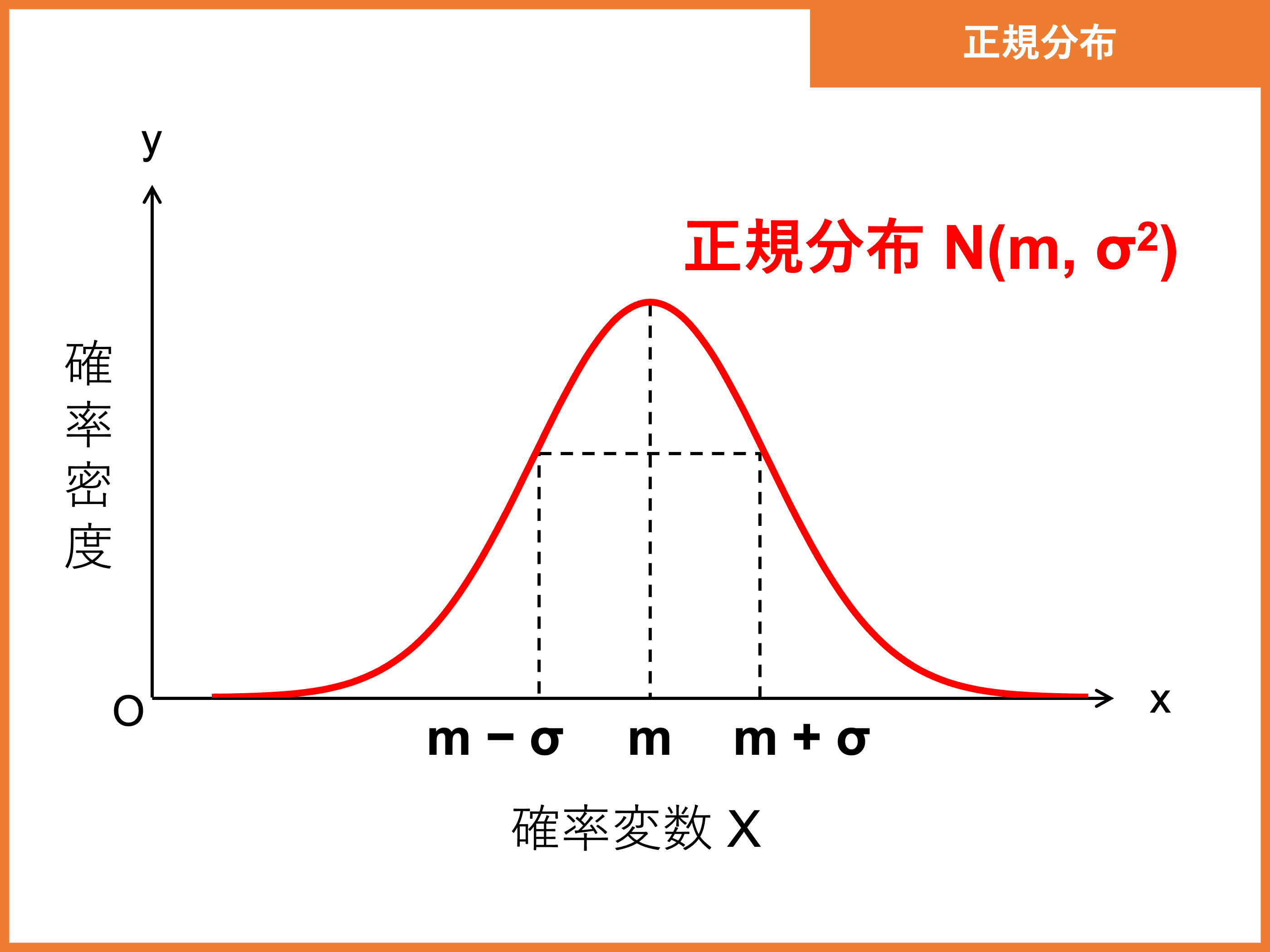
正規分布の形は、期待値(平均)\(m\) と標準偏差 \(\sigma\) だけによって決まり、\(N(m, \sigma^2)\) と表記します。
期待値(平均)\(m\)、分散 \(\sigma^2\)、標準偏差 \(\sigma\) である連続型確率変数 \(X\) が正規分布に従うとき、その正規分布を \(N(m, \sigma^2)\) と表す。
このとき、
期待値 \(E(X) = m\)
標準偏差 \(\sigma(X) = \sigma\)
(\(m\) は実数、\(\sigma\) は正の実数)
正規分布の確率密度関数
正規分布は、次の確率密度関数で表すことができます。
正規分布 \(N(m, \sigma^2)\) に従う連続型確率変数 \(X\) の確率密度関数 \(f(x)\) は
\begin{align}f(x) = \displaystyle \frac{1}{\sqrt{2\pi}\sigma}e^{− \frac{(x − m)^2}{2\sigma^2}}\end{align}
この確率密度関数そのものは覚える必要はありません。
二次関数 \(f(x) = ax^2 + bx + c\) の定数 \(a\), \(b\), \(c\) の値を変えると放物線の形や位置が変化するように、正規分布の確率密度関数 \(f(x) = \displaystyle \frac{1}{\sqrt{2\pi}\sigma}e^{− \frac{(x − m)^2}{2\sigma^2}}\) も、定数 \(m\), \(\sigma\) の値を変えると正規分布曲線の形や位置が変化する、ということを理解しましょう。

正規分布曲線の性質
正規分布曲線には、次の性質があります。
確率変数 \(X\) が正規分布 \(N(m, \sigma^2)\) に従うとき、\(X\) の分布曲線 \(y = f(x)\) は以下の性質をもつ。
- \(x\) 軸を漸近線とする
- \(x\) 軸と分布曲線の間の面積は \(1\) である
- 直線 \(x = m\) に関して対称で、\(y\) は \(x = m\) で最大値をとる
- 曲線の山は、標準偏差 \(\sigma\) が大きくなるほど低く横に広がり、\(\sigma\) が小さくなるほど軸 \(x = m\) の周りに高く集まる

性質 1, 2 はどんな確率分布でも共通の性質ですね。
性質 3, 4 は正規分布特有で、平均 \(m\), 標準偏差 \(\sigma\) の値が曲線の形を決めることを示しています。
ちなみに、正規分布 \(N(m, \sigma^2)\) に従う確率変数 \(X\) の平均値、中央値、最頻値は \(m\) に一致します。
平均値・中央値・最頻値については、以下の記事で説明しています。
 平均値・中央値・最頻値の違い!求め方、使い分け、計算問題
平均値・中央値・最頻値の違い!求め方、使い分け、計算問題
正規分布で確率を求めるには?
さて、連続型確率分布では、分布曲線下の面積が確率を示すので、確率密度関数を定積分して確率を求めるのでしたね。
「確率密度関数」と確率の求め方については、以下の記事で説明しています。
 確率密度関数とは?連続型確率変数の期待値・分散の求め方
確率密度関数とは?連続型確率変数の期待値・分散の求め方
正規分布はかなりよく登場する確率分布なのに、毎回 \(f(x) = \displaystyle \frac{1}{\sqrt{2\pi}\sigma}e^{− \frac{(x − m)^2}{2\sigma^2}}\) の定積分をするなんてめちゃくちゃ大変です(しかも高校レベルの積分の知識では対処できない)。
そこで、「正規分布を標準化して、あらかじめ計算しておいた確率(正規分布表)を利用しちゃおう!」ということになりました。
\(m\), \(\sigma\) の値が異なっても、縮尺を合わせれば対応する範囲の面積(確率)は等しいからです。

そうすれば、いちいち複雑な関数を定積分しないで、正規分布における確率を求められます。
ここから、正規分布の標準化と正規分布表の使い方を順番に説明していきます。
正規分布の標準化
ここでは、正規分布の標準化について説明します。
さて、\(m\), \(\sigma\) がどんな値の正規分布が一番シンプルで扱いやすいでしょうか?
標準偏差 \(\sigma\) は平均 \(m\) からの距離(偏差)で決まる値ですから、平均 \(m\) をグラフのど真ん中に、標準偏差 \(\sigma\) を最も単純な自然数 \(1\) で固定するのが一番シンプルです。

そこで、この正規分布 \(N(0, 1)\) を「標準正規分布」と定め、標準化のゴールとしました。
正規分布 \(N(0, 1)\) を標準正規分布という。
標準正規分布の確率密度関数
標準正規分布の確率密度関数は次のように表せます。
\(N(0, 1)\) に従う連続型確率変数 \(Z\) の確率密度関数 \(f(z)\) は
\begin{align}f(z) = \displaystyle \frac{1}{\sqrt{2\pi}}e^{− \frac{z^2}{2}}\end{align}
正規分布の確率密度関数に、\(m = 0\), \(\sigma = 1\) を代入しただけですね。
なお、元の正規分布に従う確率変数 \(X\) と区別するために、ゴールの標準正規分布に従う確率変数は \(Z\) とおきます。
標準正規分布曲線の性質
ここで、標準正規分布曲線の性質をまとめてみましょう。
標準正規分布曲線 \(y = f(z)\) は以下の性質をもつ。
- \(z\) 軸を漸近線とする
- \(x\) 軸と分布曲線の間の面積は \(1\)、\(y\) 軸が分ける \(2\) つの面積は \(0.5\) となる
\(P(Z \geq 0) = P(Z \leq 0) = 0.5\) - 直線 \(z = 0\)(\(y\) 軸)に関して対称で、\(y\) は \(z = 0\) で最大値をとる
- \(P(0 \leq Z \leq u) = p(u)\) は正規分布表を利用して求められる
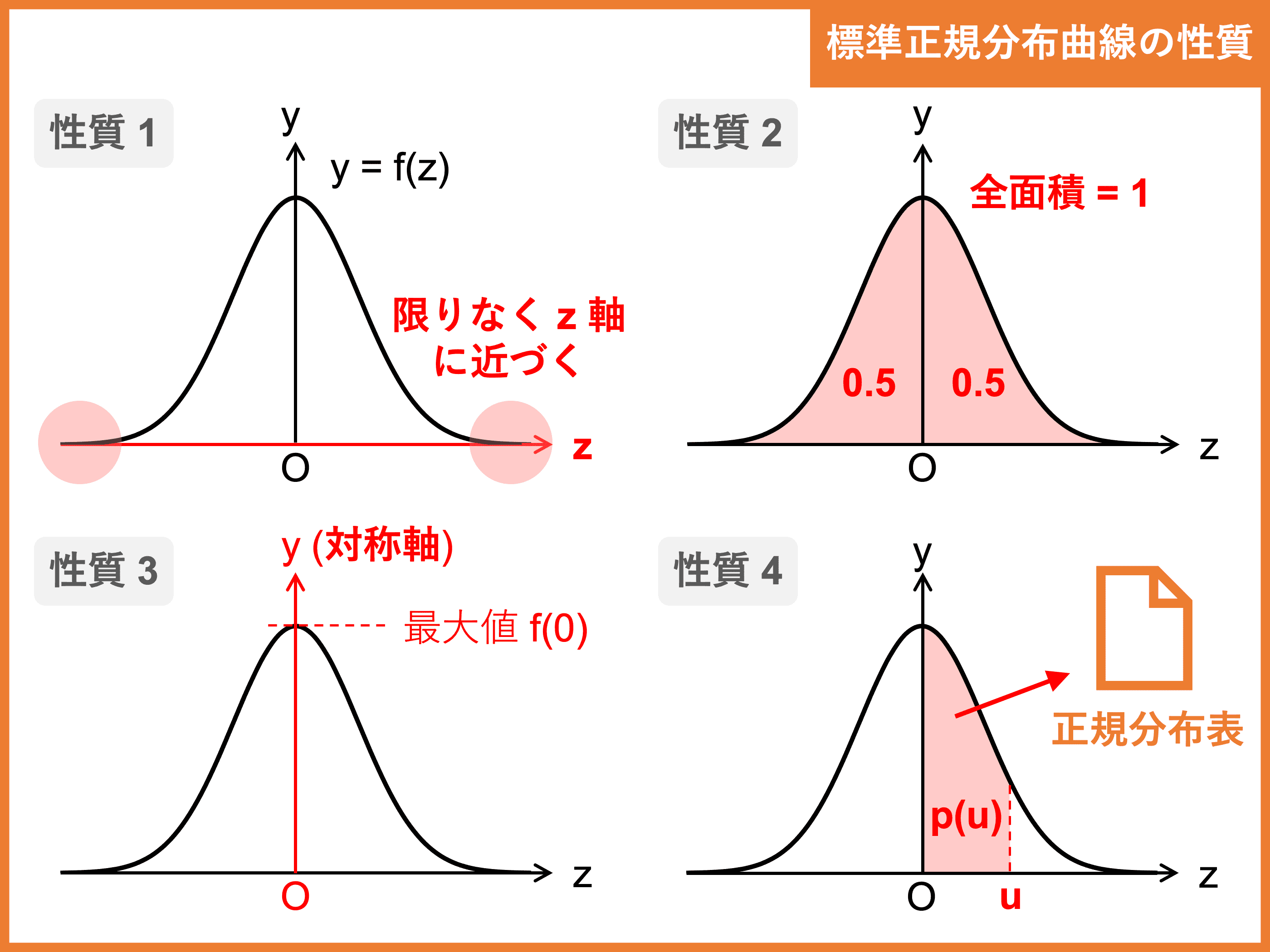
平均がど真ん中なので、面積(確率)も \(y\) 軸を境に対称でわかりやすいですね!
正規分布を標準正規分布に変換する
それでは、任意の正規分布 \(N(m, \sigma^2)\) を標準正規分布 \(N(0, 1)\) に変換する方法を確認しましょう。
確率変数 \(X\) が正規分布 \(N(m, \sigma^2)\) に従うとき、
\begin{align}Z = \displaystyle \frac{X − m}{\sigma}\end{align}
とおくと、確率変数 \(Z\) は標準正規分布 \(N(0, 1)\) に従う。
\(y = f(x)\) における \(x\) 座標 \(m \pm \sigma\) が \(y = f(z)\) における \(z\) 座標 \(0 \pm 1\) に対応し、対応する範囲の確率も等しくなります。

正規分布表の見方
ここでは、正規分布表の使い方(見方)を説明します。
正規分布表とは、標準正規分布曲線 \(y = f(z)\) に対して、以下の赤色で示された面積(確率) \(p(u) = \displaystyle \int_0^u f(z) \ dz\) の近似値(小数第 \(5\) 位で四捨五入)を表したものです。
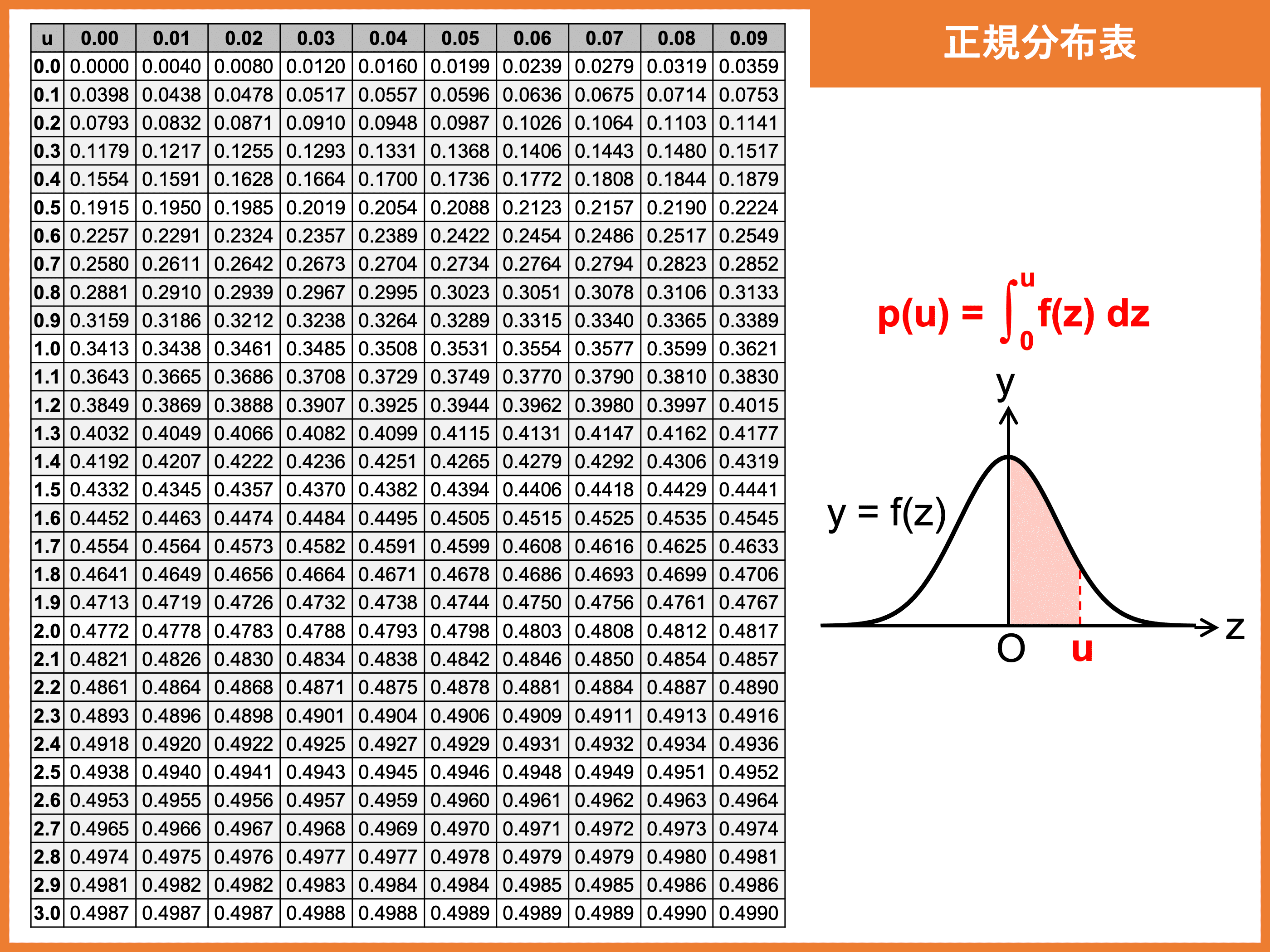
表の左端の列が \(|u|\) の小数第 \(1\) 位まで、上端の行が \(|u|\) の小数第 \(2\) 位を表していて、直行表のように見ることで \(P(0 \leq Z \leq u) = p(u)\) の確率を求められます。

正規分布表には \(y\) 軸からの面積(確率)しか載っていないので、\(y\) 軸をまたぐ面積や \(y\) 軸を通過しない面積を求めるには、次のように確率を足し引きします。
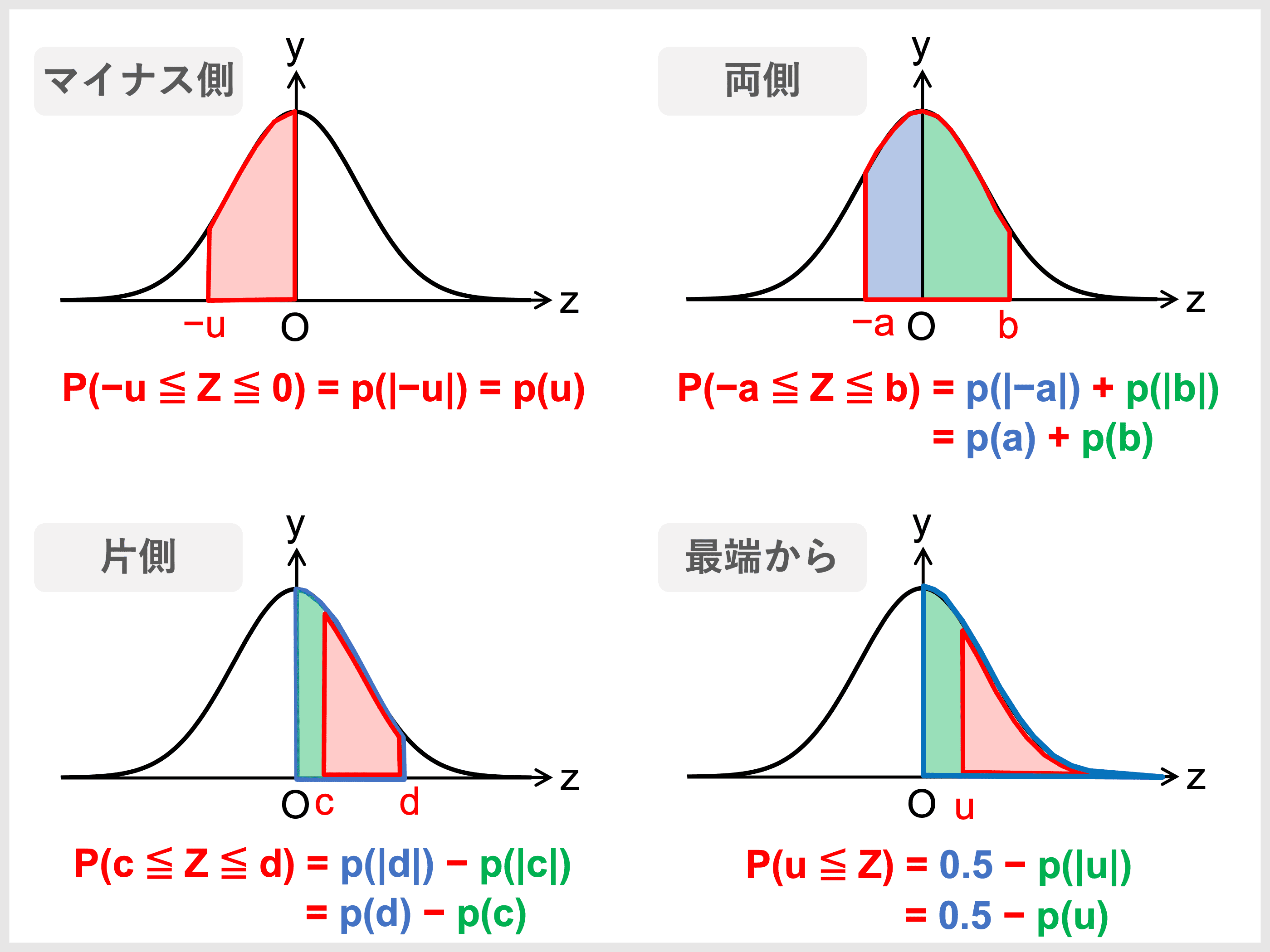
例題「正規分布表を用いて確率を求める」
例題を通して、正規分布表を用いて確率を求める手順を説明します。
確率変数 \(X\) が正規分布 \(N(15, 3^2)\) に従うとき、次の確率を求めよ。
(1) \(P(X \leq 18)\)
(2) \(P\left(12 \leq X \leq \displaystyle \frac{57}{4}\right)\)
まずは、正規分布を標準正規分布へ変換します。
\(Z = \displaystyle \frac{X − 15}{3}\) とおくと、\(Z\) は標準正規分布 \(N(0, 1)\) に従う。
STEP.1 の式を使って、問題の \(X\) の範囲を \(Z\) の範囲に変換します。
(1)
\(P(X \leq 18)\)
\(= P\left(Z \leq \displaystyle \frac{18 − 15}{3}\right)\)
\(= P(Z \leq 1)\)
(2)
\(P\left(12 \leq X \leq \displaystyle \frac{57}{4}\right)\)
\(= P\left(\displaystyle \frac{12 − 15}{3} \leq Z \leq \displaystyle \frac{\frac{57}{4} − 15}{3}\right)\)
\(= P(−1 \leq Z \leq −0.25)\)
簡単な図を書いて、\(Z\) の範囲を図示します。
このとき、正規分布表のどの値をとってくればよいかを検討しましょう。

(1) \(P(Z \leq 1) = 0.5 + p(1.00)\)
(2) \(P(−1 \leq Z \leq −0.25) = p(1.00) − p(0.25)\)
あとは、正規分布表から必要な値を取り出して足し引きするだけです。

(1)
正規分布表より、\(p(1.00) = 0.3413\) であるから
\(\begin{align}P(X \leq 18) &= 0.5 + p(1.00)\\&= 0.5 + 0.3413\\&= 0.8413\end{align}\)
(2)
正規分布表より、\(p(1.00) = 0.3413\), \(p(0.25) = 0.0987\) であるから
\(\begin{align}P\left(12 \leq X \leq \displaystyle \frac{57}{4}\right) &= p(1.00) − p(0.25)\\&= 0.3413 − 0.0987\\&= 0.2426\end{align}\)
答え: (1) \(0.8413\)、(2) \(0.2426\)
慣れてきたら、一連の計算をまとめてできるようになりますよ!
正規分布の標準偏差とデータの分布
一般に、任意の正規分布 \(N(m, \sigma)\) において次のことが言えます。
正規分布 \(N(m, \sigma)\) に従う確率変数 \(X\) について、
- \(m \pm 1\sigma\) の範囲に全データの約 \(68.3\) %
- \(m \pm 2\sigma\) の範囲に全データの約 \(95.4\) %
- \(m \pm 3\sigma\) の範囲に全データの約 \(99.7\) %
が分布する。
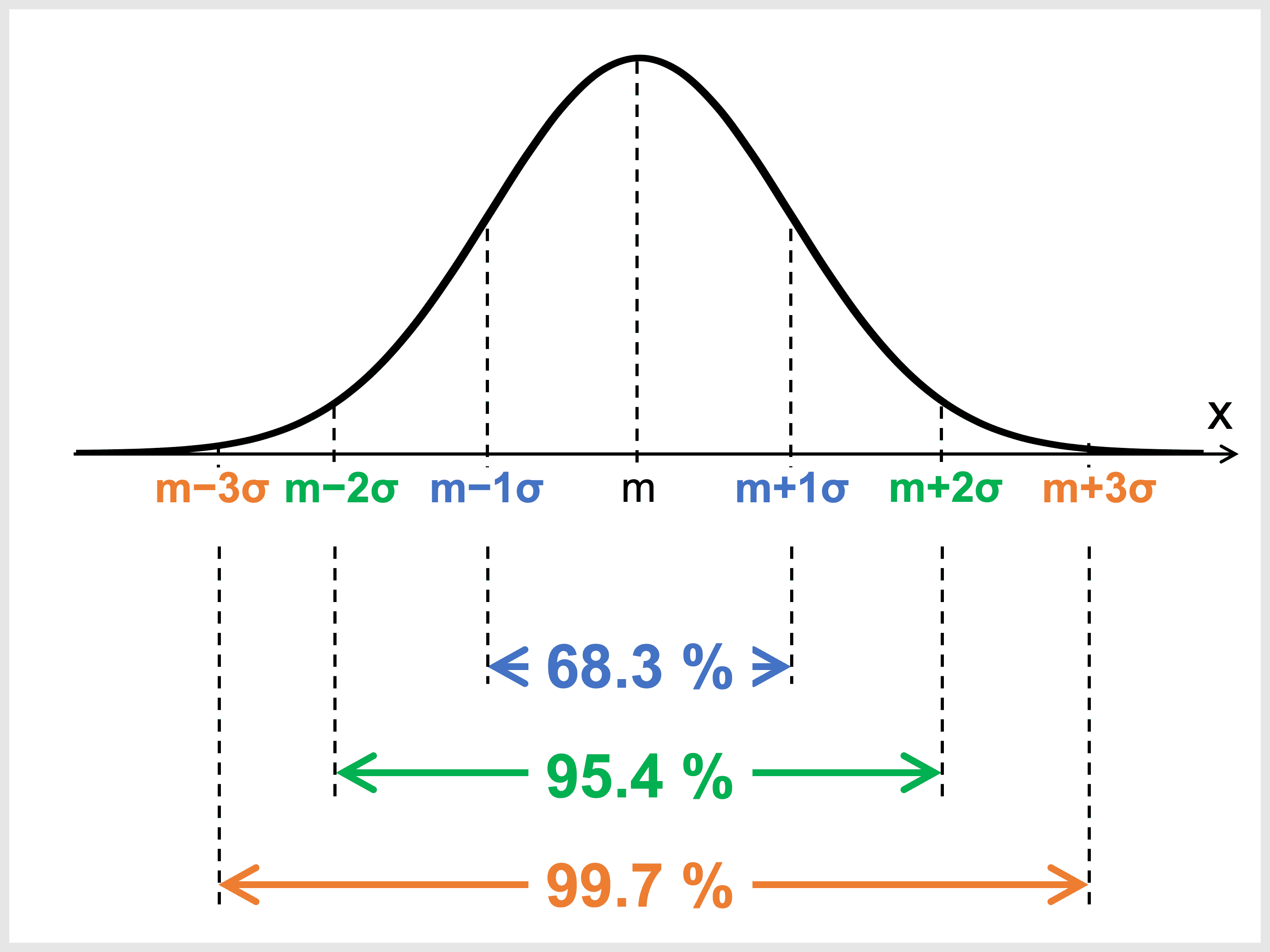
これは、正規分布表から実際に \(\pm1\) 標準偏差、\(\pm2\) 標準偏差、\(\pm3\) 標準偏差の確率を求めてみるとわかります。
\(P(−1 \leq Z \leq 1) = 2 \cdot 0.3413 = 0.6826\)
\(P(−2 \leq Z \leq 2) = 2 \cdot 0.4772 = 0.9544\)
\(P(−3 \leq Z \leq 3) = 2 \cdot 0.49865 = 0.9973\)
このように、正規分布では標準偏差を基準に「ある範囲にどのくらいのデータが分布するのか」が簡単にわかります。
こうした「基準」としての価値から、標準偏差という指標が重宝されているのです。
正規分布の計算問題
最後に、正規分布の計算問題に挑戦しましょう。
計算問題①「身長と正規分布」
ある高校の男子 \(400\) 人の身長 \(X\) が、平均 \(171.9 \ \mathrm{cm}\)、標準偏差 \(5.4 \ \mathrm{cm}\) の正規分布に従うものとする。このとき、次の問いに答えよ。
(1) 身長 \(180 \ \mathrm{cm}\) 以上の男子生徒は約何人いるか。
(2) 高い方から \(90\) 人の中に入るには、何 \(\mathrm{cm}\) 以上あればよいか。

身長 \(X\) が従う正規分布を標準化し、求めるべき面積をイメージしましょう。
(2) では、高い方から \(90\) 人の割合を求めて、確率(面積)から身長を逆算します。
身長 \(X\) は正規分布 \(N(171.9, 5.4^2)\) に従うから、
\(Z = \displaystyle \frac{X − 171.9}{5.4}\) とおくと、\(Z\) は標準正規分布 \(N(0, 1)\) に従う。
(1)
\(\begin{align}P(X \geq 180) &= P\left(Z \geq \displaystyle \frac{180 − 171.9}{5.4}\right)\\&= P\left(Z \geq \displaystyle \frac{8.1}{5.4}\right)\\&≒ P(Z \geq 1.5)\\&= 0.5 − p(1.5)\\&= 0.5 − 0.4332\\&= 0.0668\end{align}\)
\(400 \times 0.0668 = 26.72\) より、求める生徒の人数は約 \(27\) 人
答え: 約 \(27\) 人
(2)
身長が \(x \ \mathrm{cm}\) 以上であれば高い方から \(90\) 人の中に入るとする。
ここで、
\(\displaystyle \frac{90}{400} = 0.225 < 0.5\) より、
\(P(Z \geq u) = 0.225\) とすると
\(\begin{align}P(0 \leq Z \leq u) &= 0.5 − P(Z \geq u)\\&= 0.5 − 0.225\\&= 0.275\end{align}\)
よって、正規分布表から \(u ≒ 0.755\)
これに対応する \(x\) の値は
\(0.755 = \displaystyle \frac{x − 170.9}{5.4}\)
\(\begin{align}x &= 0.755 \cdot 5.4 + 170.9\\&= 4.077 + 170.9\\&= 174.977\end{align}\)
したがって、\(175.0 \ \mathrm{cm}\) 以上あればよい。
答え: \(175.0 \ \mathrm{cm}\) 以上
計算問題②「製品の長さと不良品」
ある製品 \(1\) 万個の長さは平均 \(69 \ \mathrm{cm}\)、標準偏差 \(0.4 \ \mathrm{cm}\) の正規分布に従っている。長さ \(70 \ \mathrm{cm}\) 以上の製品を不良品とみなすとき、この \(1\) 万個の製品の中には何個の不良品が含まれると予想されるか。
標準正規分布を用いて不良品の割合を調べ、予想個数を求めましょう。
製品の長さ \(X\) は正規分布 \(N(69, 0.4^2)\) に従うから、
\(Z = \displaystyle \frac{X − 69}{0.4}\) とおくと、\(Z\) は標準正規分布 \(N(0, 1)\) に従う。
よって
\(\begin{align}P(Z \geq 70) &= P\left(Z \geq \displaystyle \frac{70 − 69}{0.4}\right)\\&= P(Z \geq 2.5)\\&= 0.5 − p(2.5)\\&= 0.5 − 0.4938\\&= 0.0062\end{align}\)
したがって、\(1\) 万個の製品中の不良品の予想個数は
\(10,000 \times 0.0062 = 62\)(個)
答え: \(62\) 個
以上で問題も終わりです!
正規分布はいろいろなところで活用するので、基本的な計算問題への対処法は確実に理解しておきましょう。
正規分布は、統計的な推測においてとても重要な役割を果たします。
詳しくは、以下の記事で説明していきます!
 母集団と標本とは?統計調査の意味や求め方をわかりやすく解説!
母集団と標本とは?統計調査の意味や求め方をわかりやすく解説!
 信頼区間とは?母平均・母比率の推定の公式や問題の解き方
信頼区間とは?母平均・母比率の推定の公式や問題の解き方
正規分布の標準化
確率変数 が正規分布 (,) に従うとき、
=−/
とおくと、確率変数 は標準正規分布 (0,1) に従う。
となっていますが、「N(m,^2)に従うとき」ではないでしょうか?
この度はコメントいただきありがとうございます。
該当部分を修正いたしました。
このようにご指摘いただけるととても助かります。
今後ともどうぞ当サイトをよろしくお願いいたします。