この記事では、「分散」の公式や求め方をわかりやすく解説していきます。
計算問題の解き方もていねいに説明していくので、ぜひこの記事を通してマスターしてくださいね!
目次
分散とは?
分散とは、データの散らばり度合い(ばらつき)を表す値のことをいいます。
つまり、「集めたデータが平均値からどれくらい離れているか」を示す値です。
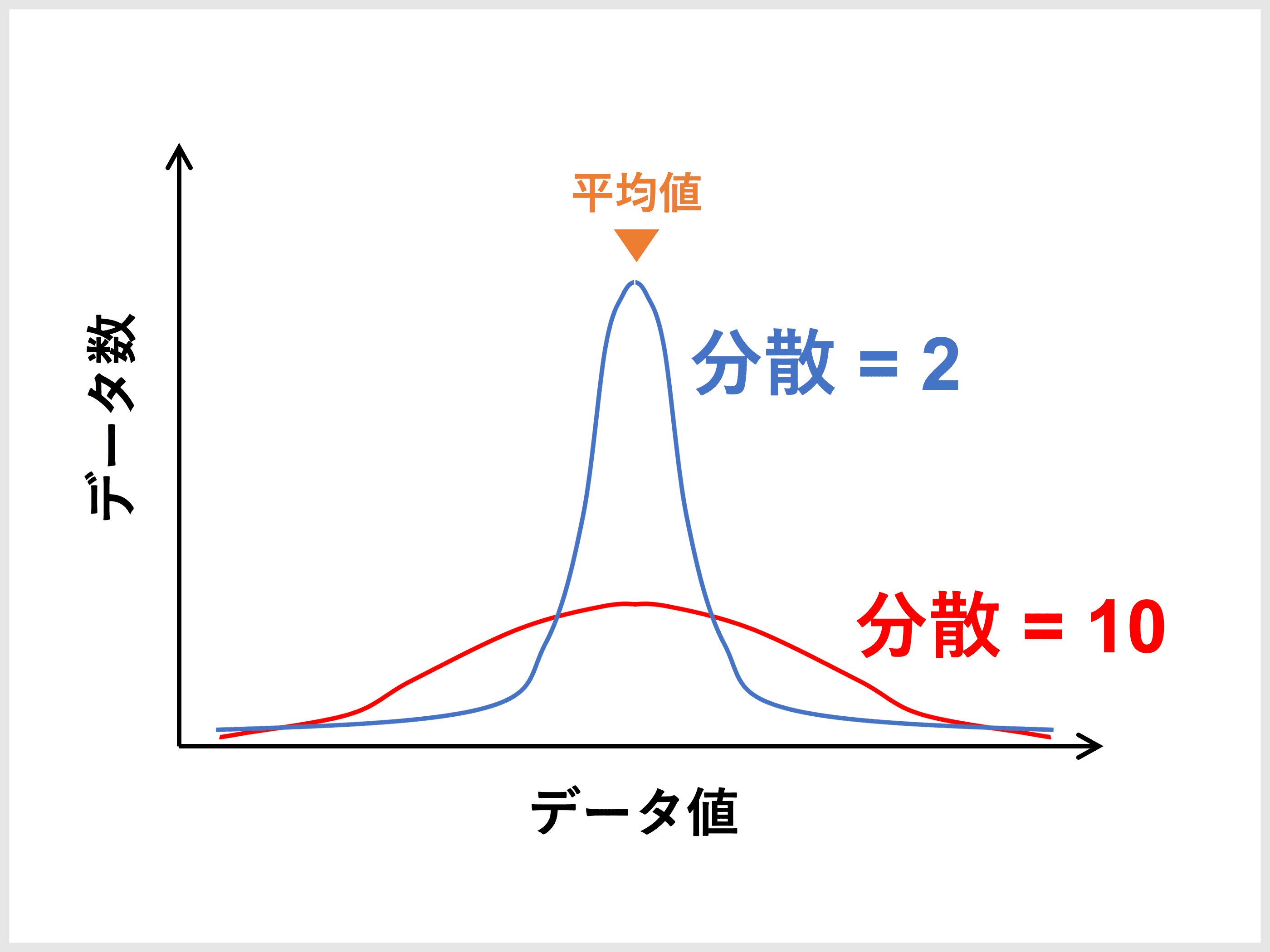
正規分布を例に分散の大きさを比較してみると、分散の値が大きいほどすそ広がりの分布に、小さいほど平均値周辺にギュッと固まった分布になります。
分散の記号
分散は、「\(\sigma^2\)」「\(s^2\)」「\(V[X]\)」などの記号で表されます。
- \(\sigma^2\):母集団の分散
- \(s^2\):標本の分散
- \(V[X]\):確率変数 \(X\) の分散
データの分析の問題では「\(s^2\)」を、確率分布の問題では「\(V[X]\)」を見ることが多いでしょう。
母集団は「調査の対象全体」、標本は「母集団から抜き出された対象の一部」を指します。
統計調査において母集団全体のデータを集めるのはなかなか難しいので、標本を扱うことが多いです。
 母集団と標本とは?統計調査の意味や求め方をわかりやすく解説!
母集団と標本とは?統計調査の意味や求め方をわかりやすく解説!
分散の公式
分散には、次の \(2\) 通りの公式があります。
公式① 偏差の 2 乗の平均
分散は、偏差(個々のデータと平均値との差)の \(2\) 乗の平均値として求められます。
分散を \(s^2\)、データの総数を \(n\)、それぞれのデータの値を \(x_1\), \(x_2\), \(\cdots\), \(x_n\)、平均値を \(\overline{x}\) とすると、
\begin{align}\color{red}{\displaystyle s^2 = \frac{1}{n} \{(x_1 − \overline{x})^2 + (x_2 − \overline{x})^2 + \cdots + (x_n − \overline{x})^2\}}\end{align}
(見切れる場合は横へスクロール)
偏差の \(2\) 乗の和を求め、それをデータの総数で割れば、分散が求められますね。
公式② (2 乗の平均) − (平均の 2 乗)
分散は (データの \(2\) 乗の平均値) − (データの平均値の \(2\) 乗) でも求められます。
分散を \(s^2\)、データの値を \(x\)、データの平均値を \(\overline{x}\) とすると、
\begin{align}\color{red}{s^2 = \overline{x^2} − (\overline{x})^2}\end{align}
こちらの公式は、平均値のキリが悪いとき(小数を含むなど)に使うのがオススメです。
平均値が小数を含む場合、公式①だと小数の \(2\) 乗の計算をたくさんしないといけませんが、公式②なら \(1\) 回で済むためです。
分散 \(s^2\) がわかれば、標準偏差 \(s\) もすぐに求められます。
 標準偏差とは?意味や求め方、計算問題をわかりやすく解説!
標準偏差とは?意味や求め方、計算問題をわかりやすく解説!
分散の求め方
次の例題を通して、分散の求め方を公式ごとに説明します。
次のデータは、\(5\) 人の学生が一日に読書する時間 \(x\) (分) である。
\(5\), \(30\), \(10\), \(40\), \(15\)
このデータの分散 \(s^2\) を求めなさい。
公式①で求める手順
まずは公式①を使った求め方です。
まず、このデータの平均値 \(\overline{x}\) を求めます。
平均値 \(\overline{x}\) を求めるには、すべてのデータの値を足してデータの総数で割ります。
\(\begin{align} \overline{x} &= \frac{x_1 + x_2 + x_3 + x_4 + x_5}{5} \\&= \frac{5 + 30 + 10 + 40 + 15}{5} \\ &= \frac{100}{5} \\ &= 20 \end{align}\)
次に、それぞれのデータの値から平均値を引いた偏差 \(x_i − \overline{x}\) を求めます。
\(x_1 − \overline{x} = 5 − 20 = − 15\)
\(x_2 − \overline{x} = 30 − 20 = 10\)
\(x_3 − \overline{x} = 10 − 20 = − 10\)
\(x_4 − \overline{x} = 40 − 20 = 20\)
\(x_5 − \overline{x} = 15 − 20 = − 5\)
先ほどの偏差を \(2\) 乗していきます。
\((x_1 − \overline{x})^2 = (− 15)^2 = 225\)
\((x_2 − \overline{x})^2 = 10^2 = 100\)
\((x_3 − \overline{x})^2 = (− 10)^2 = 100\)
\((x_4 − \overline{x})^2 = 20^2 = 400\)
\((x_5 − \overline{x})^2 = (− 5)^2 = 25\)
偏差の \(2\) 乗の合計をデータの総数で割ると、分散 \(s^2\) が求まります。
\(s^2\)
\(= \displaystyle \frac{(x_1 − \overline{x})^2 + (x_2 − \overline{x})^2 + \cdots + (x_5 − \overline{x})^2}{5}\)
\(= \displaystyle \frac{225 + 100 + 100 + 400 + 25}{5}\)
\(= \displaystyle \frac{850}{5}\)
\(= 170\)
となり、このデータの分散は \(\color{red}{s^2 = 170}\) と求められます。
表を使って公式①で求める手順
公式①を使う計算は、表を使うと楽にできます。
まずは表の体裁を作ります。
「データ番号 \(i\)」「各データ \(x_i\)」「偏差 \(x_i − \overline{x}\)」「偏差の \(2\) 乗 \((x_i − \overline{x})^2\)」の列を作り、末尾に合計行、平均行を追加します。(行・列は入れ替えてもOKです!)
そして、データ番号とデータを埋めておきましょう。
| \(i\) | \(x_i\) | \(x_i − \overline{x}\) | \((x_i − \overline{x})^2\) |
| \(1\) | \(5\) | ||
| \(2\) | \(30\) | ||
| \(3\) | \(10\) | ||
| \(4\) | \(40\) | ||
| \(5\) | \(15\) | ||
| 合計 | |||
| 平均 |
データ列を足し算し、データの合計を出します。
合計をデータの個数 \(5\) で割れば平均値 \(\overline{x}\) がすぐに出せますね。
| \(i\) | \(x_i\) | \(x_i − \overline{x}\) | \((x_i − \overline{x})^2\) |
| \(1\) | \(5\) | ||
| \(2\) | \(30\) | ||
| \(3\) | \(10\) | ||
| \(4\) | \(40\) | ||
| \(5\) | \(15\) | ||
| 合計 | \(100\) | ||
| 平均 | \(20\) |
偏差は、データ列 \(x_i\) の値から平均値 \(\overline{x}\) を引くと求まります。
| \(i\) | \(x_i\) | \(x_i − \overline{x}\) | \((x_i − \overline{x})^2\) |
| \(1\) | \(5\) | \(−15\) | |
| \(2\) | \(30\) | \(10\) | |
| \(3\) | \(10\) | \(−10\) | |
| \(4\) | \(40\) | \(20\) | |
| \(5\) | \(15\) | \(−5\) | |
| 合計 | \(100\) | − | |
| 平均 | \(20\) | − |
偏差の \(2\) 乗 \((x_i − \overline{x})^2\) は、偏差列の値を \(2\) 乗するだけですね。
| \(i\) | \(x_i\) | \(x_i − \overline{x}\) | \((x_i − \overline{x})^2\) |
| \(1\) | \(5\) | \(−15\) | \(225\) |
| \(2\) | \(30\) | \(10\) | \(100\) |
| \(3\) | \(10\) | \(−10\) | \(100\) |
| \(4\) | \(40\) | \(20\) | \(400\) |
| \(5\) | \(15\) | \(−5\) | \(25\) |
| 合計 | \(100\) | − | |
| 平均 | \(20\) | − |
それらの合計を求め、データの個数 \(5\) で割れば、それが分散となります!
| \(i\) | \(x_i\) | \(x_i − \overline{x}\) | \((x_i − \overline{x})^2\) |
| \(1\) | \(5\) | \(−15\) | \(225\) |
| \(2\) | \(30\) | \(10\) | \(100\) |
| \(3\) | \(10\) | \(−10\) | \(100\) |
| \(4\) | \(40\) | \(20\) | \(400\) |
| \(5\) | \(15\) | \(−5\) | \(25\) |
| 合計 | \(100\) | − | \(850\) |
| 平均 | \(20\) | − | 分散 \(\color{red}{170}\) |
表を使うと、数式を長々と書くよりも頭の中が整理できるので、特にデータの個数が多いときにオススメです!
公式②で求める手順
続いて、公式②を使った求め方です。
まずは、公式①と同様、データの平均値 \(\overline{x}\) を求めます。
\(\begin{align} \overline{x} &= \frac{x_1 + x_2 + x_3 + x_4 + x_5}{5} \\&= \frac{5 + 30 + 10 + 40 + 15}{5} \\ &= \frac{100}{5} \\ &= 20 \end{align}\)
データの平均値を \(2\) 乗します。
\((\overline{x})^2 = 20^2 = 400\)
個々のデータの \(2\) 乗の和をデータの個数で割り、その平均を求めます。
\(\begin{align} \overline{x^2} &= \frac{5^2 + 30^2 + 10^2 + 40^2 + 15^2}{5} \\ &= \frac{25 + 900 + 100 + 1600 + 225}{5} \\ &= \frac{2850}{5} \\ &= 570 \end{align}\)
最後にデータの \(2\) 乗の平均値 \(\overline{x^2}\) からデータの平均値の \(2\) 乗 \((\overline{x})^2\) を引くと、分散 \(s^2\) が求まります。
\(\begin{align} s^2 &= \overline{x^2} − (\overline{x})^2 \\ &= 570 − 400 \\ &= \color{red}{170} \end{align}\)
分散の計算問題
では最後に、分散の計算問題を解いてみましょう!
計算問題①「公式を使い分ける」
次のデータの分散を小数第 \(1\) 位まで求めなさい。
(1) \(18\), \(29\), \(24\), \(42\), \(7\), \(36\)
(2) \(15\), \(4\), \(21\), \(8\), \(17\), \(16\)

まずはデータの平均値を求めてみましょう。
データの平均値が小数なら公式②がオススメです。
(1)
このデータの平均値は、
\(\begin{align} \overline{x} &= \frac{18 + 29 + 24 + 42 + 7 + 36}{6} \\ &= \frac{156}{6} \\ &= 26 \end{align}\)
分散の公式より、
\(s^2\)
\(= \displaystyle \frac{1}{6} \{(18 − 26)^2 + (29 − 26)^2 + (24 − 26)^2 + (42 − 26)^2 + (7 − 26)^2 + (36 − 26)^2\}\)
\(= \displaystyle \frac{1}{6} \{(−8)^2 + 3^2 + (−2)^2 + 16^2 + (−19)^2 + 10^2\}\)
\(= \displaystyle \frac{1}{6} (64 + 9 + 4 + 256 + 361 + 100)\)
\(= \displaystyle \frac{1}{6} \cdot 794\)
\(= 132.3333\cdots\)
\(≒ 132.3\)
(見切れる場合は横へスクロール)
答え: \(132.3\)
(2)
このデータの平均値は、
\(\begin{align}\overline{x} &= \frac{15 + 4 + 21 + 8 + 17 + 16}{6} \\ &= \frac{81}{6} \\ &= 13.5 \end{align}\)
また、
\(\overline{x^2}\)
\(= \displaystyle \frac{15^2 + 4^2 + 21^2 + 8^2 + 17^2 + 16^2}{6}\)
\(= \displaystyle \frac{225 + 16 + 441 + 64 + 289 + 256}{6}\)
\(= \displaystyle \frac{1291}{6}\)
\(= 215.166\cdots\)
\(≒ 215.17\)
分散の公式より、
\(\begin{align}s^2 &= \overline{x^2} − (\overline{x})^2\\&= 215.17 − (13.5)^2\\&= 215.17 − 182.25\\&= 32.92\\&≒ 32.9\end{align}\)
答え: \(\color{red}{32.9}\)
計算問題②「表を使って分散を求める」
次のデータ \(x\) の分散を求めなさい。
| 番号 | \(1\) | \(2\) | \(3\) | \(4\) | \(5\) | \(6\) | \(7\) | \(8\) | \(9\) | \(10\) |
| \(x\) | \(7\) | \(2\) | \(4\) | \(9\) | \(8\) | \(3\) | \(5\) | \(1\) | \(5\) | \(6\) |
データが表で示されているので、この表を活用して平均値や偏差を計算すると楽ですね。
各データの平均値、偏差、偏差の \(2\) 乗などを計算すると次のようになる。

したがって、このデータの分散は \(s^2 = 6\)
答え: \(6\)
【発展】分散分析と多重比較
最後に、分散を利用したデータの分析手法、「分散分析」と「多重比較」について少しだけ説明します。
研究活動やビジネスにおいて、集めたデータから何が言えるかを導くときに役立つ分析手法です。
発展的な内容なので、参考程度にとらえてくださいね。
分散分析
分散分析とは、複数のデータの母平均に、因子(研究の対象となる要因)によって明確に差があるかを検定する分析手法です。
平均値と分散を合わせて見比べることにより、平均値の差が因子によるものなのかを判断できます。
一般的に、実験誤差による分散が大きすぎると、因子間で平均値の差があるとは判断されにくくなります。
分散分析では、注目する要素数に応じて「一元配置」「二元配置」などの分析方法があります。
一元配置では、\(1\) つの因子に注目し、因子の条件間で母平均に違いがあるかだけを調べることができます。
それに対し、二元配置以上(多元配置)では、複数の因子に注目し、因子の条件間での母平均の違いだけでなく、因子間で相互作用があるかも調べることができます。
分析対象の例には次のようなものがあります。
- 一元配置分散分析
任意の日本人、アメリカ人、イギリス人 \(10\) 人ずつの身長を計測し、\(3\) ヶ国の平均身長に差があるかどうかを調べる。
要素:身長、因子:国籍 - 二元配置分散分析
任意の日本人、アメリカ人、イギリス人 \(10\) 人ずつの性別を調べた上で身長を計測し、\(3\) ヶ国の平均身長に差があるかどうかを調べる。また、性別が身長に何らかの効果をもたらすかを調べる。
要素:身長、因子:国籍、性別
具体的な分析方法については、統計の参考書などを参考にしてみてください。
多重比較
多重比較とは、独立した群が \(3\) つ以上あるとき、どの群とどの群の平均値に有意差があるかを検定する手法です。
分散分析では、複数のデータ群のうち、どれか \(1\) つ以上の群間に差があるということしかわからず、どの群に差があるのかまではわかりません。
そのため、一般的に、そもそも群間に差があるかどうかを分散分析で調べたあと、どの群の間に差があるかを調べるために多重比較を用いることが多いです。
多重比較には、取り扱うデータの性質に応じて LSD、Bonferoni、Tukey、Dunnett などさまざまな方法があり、多重比較の対象や方法によって事前の分散分析が必要な場合と必要ない場合があります。
これらについても、詳細は参考書等を参考にしてください。
データ分析は奥深く、ハマるととても便利で、楽しい学問ですよ!
以上で分散についての解説は終わりです。
分散についての理解が深まれば幸いです!