数Iの一大分野、「データの分析」に関するさまざまな公式をまとめていきます。
詳細記事へのリンクも載せていますので、気になる問題や解き方があればぜひそちらを参考にしてください。
また、最後に公式の覚え方や求め方のちょっとした裏ワザも紹介しているので、テスト前の最終確認に活用してくださいね!
目次
データの代表値
データ全体の特徴を表す数値を代表値といいます。
代表値には、「平均値」「中央値」「最頻値」があり、データの種類や目的によって使い分けます。
 平均値・中央値・最頻値の違い!求め方、使い分け、計算問題
平均値・中央値・最頻値の違い!求め方、使い分け、計算問題
平均値 \(\bar{x}\)
平均値とは、データの値の合計をデータの総数で割った値です。
\(n\) 個のデータ \(x_1\), \(x_2\), \(x_3\), \(\cdots\), \(x_n\) があるとき、データの平均値 \(\bar{x}\) は
\begin{align}\displaystyle \bar{x} =\frac{x_1 + x_2 + x_3 + \cdots + x_n}{n}\end{align}
中央値 \(M_e\)
中央値とは、データの値を大きさ順に並べたとき、中央の位置にくる値です。
\(n\) 個のデータを小さい順に \(x_{(1)}\), \(x_{(2)}\), \(x_{(3)}\), \(\cdots\), \(x_{(n)}\) と並べたとき、データの中央値 \(M_e\) は
- \(n\) が奇数の場合
\begin{align}\displaystyle M_e = x_{(\frac{n + 1}{2})}\end{align} - \(n\) が偶数の場合
\begin{align}\displaystyle M_e = \frac{x_{(\frac{n}{2})} + x_{(\frac{n}{2} + 1)}}{2}\end{align}
最頻値 \(M_o\)
最頻値とは、データの中で最も個数(出現頻度)の多い値です。
\(n\) 個のデータ \(x_1\), \(x_2\), \(x_3\), \(\cdots\), \(x_n\) のうち、最も頻繁に観測された数値 \(x\) が最頻値 \(M_o\) である。
データの散らばりの可視化
得られたデータを図表に整理して可視化すると、データの散らばりや傾向がつかみやすくなります。
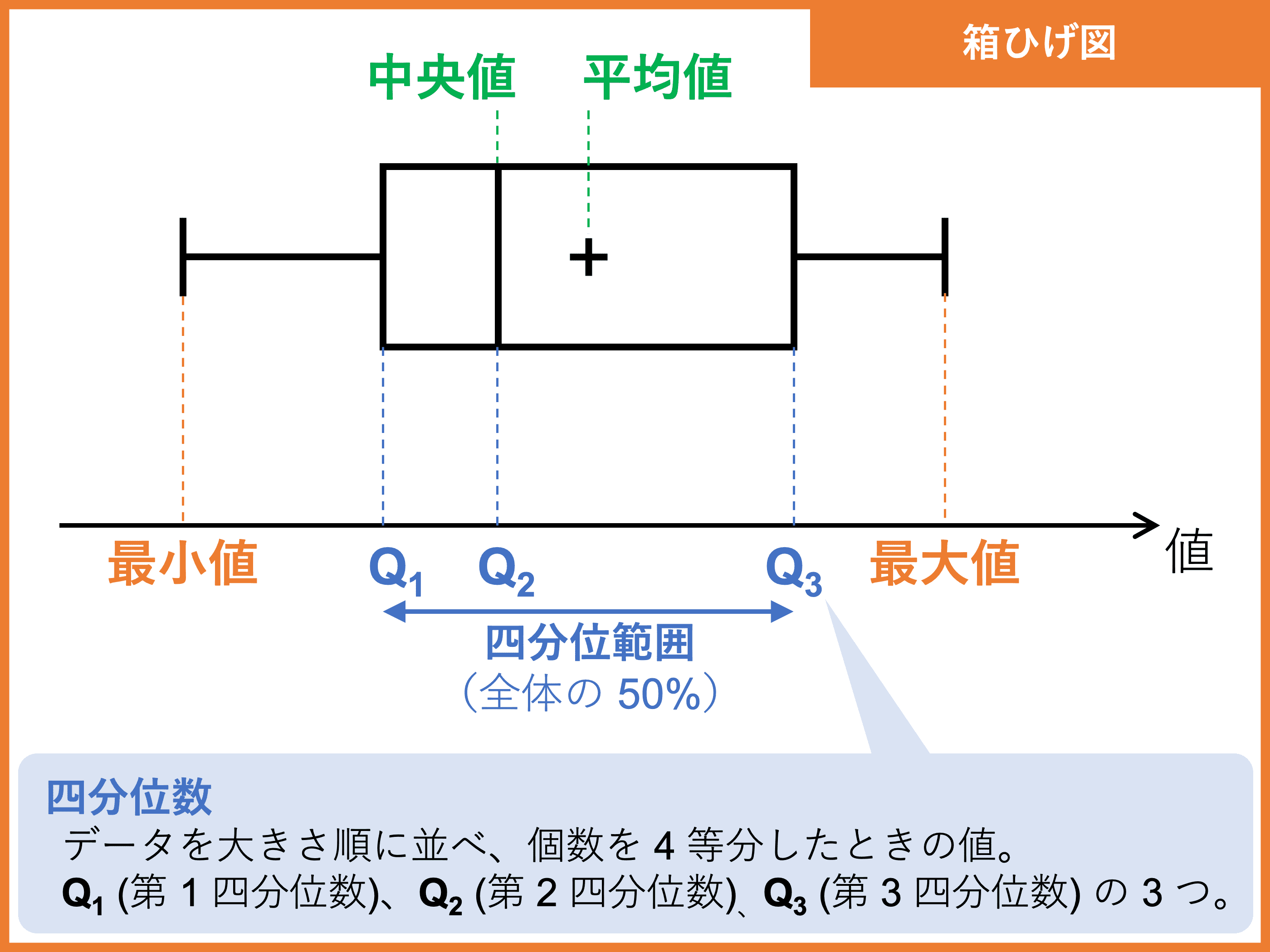
箱ひげ図
箱ひげ図とは、データの「最小値」「最大値」「中央値」「平均値」「第 \(1\) 四分位数」「第 \(3\) 四分位数」をまとめた図です。
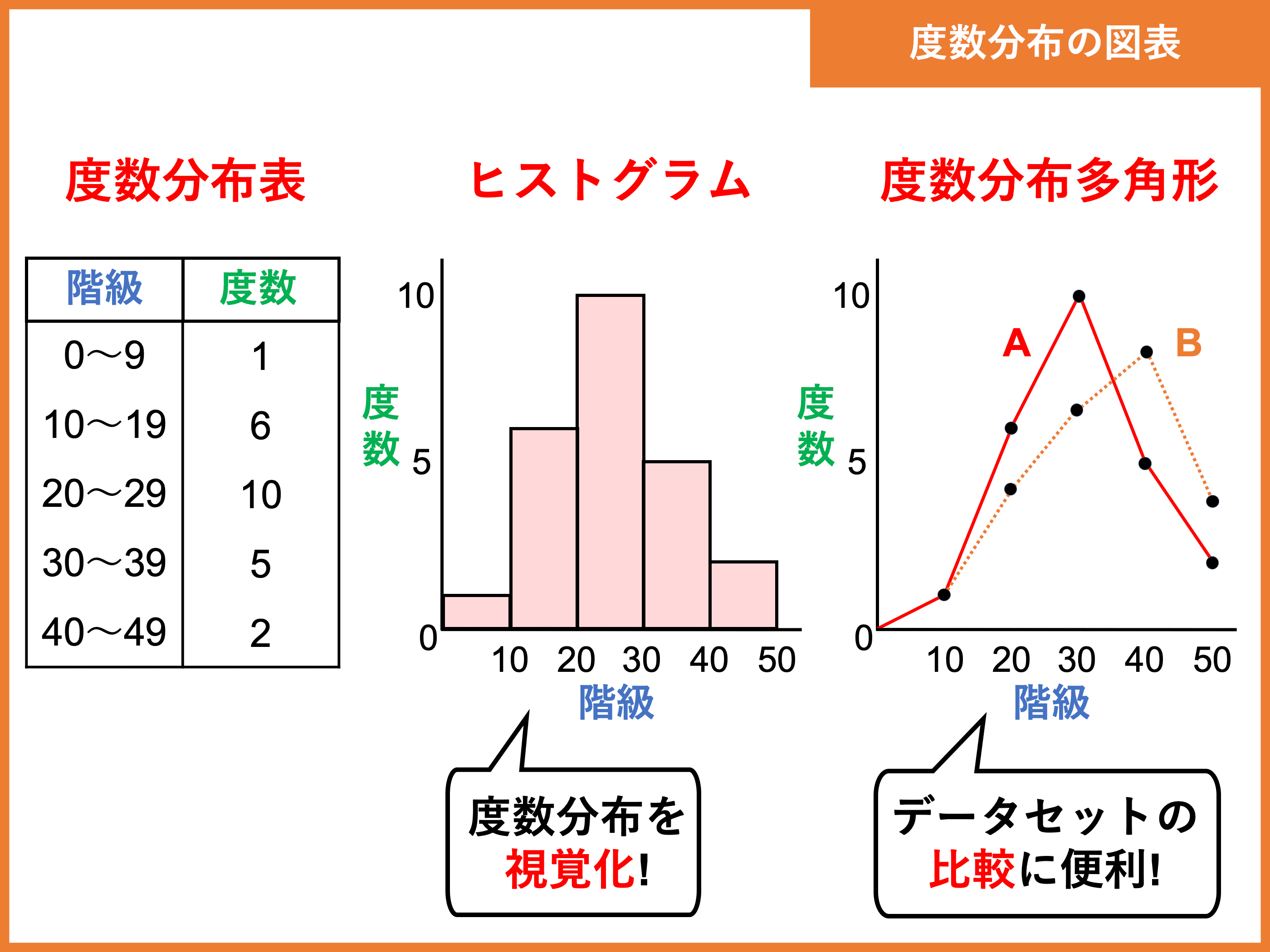
度数分布とヒストグラム
集めたデータをいくつかの区間(= 階級)に分け、各区間のデータ個数を可視化したものを「度数分布」といいます。
度数分布を表にまとめたものは「度数分布表」、棒グラフで表したものは「ヒストグラム」、折れ線グラフで表したものは「度数分布多角形」といいます。
 度数分布表の読み方と作り方、代表値の求め方を徹底解説!
度数分布表の読み方と作り方、代表値の求め方を徹底解説!
 ヒストグラムとは?書き方(階級や幅の決め方)を解説
ヒストグラムとは?書き方(階級や幅の決め方)を解説
データの散らばりの数値化
データの散らばり具合を客観的に評価するいくつかの指標が存在します。
偏差 \(x_i − \bar{x}\)
個々のデータとデータ全体の平均値との差を「偏差」といいます。
個々のデータを \(x_i\)、データの平均値を \(\bar{x}\) とすると、
\begin{align}(\text{偏差}) = x_i − \bar{x}\end{align}
偏差は平均値からのズレなので、正の値をとることもあれば負の値をとることもあります。
分散 \(s^2\)
分散とは、データの散らばり度合いやばらつきを表す値で、次の \(2\) とおりの求め方があります。
分散を \(s^2\)、データの総数を \(n\)、それぞれのデータの値を \(x_1\), \(x_2\), \(\cdots\), \(x_n\)、平均値を \(\bar{x}\) とすると、
\begin{align}\displaystyle s^2 = \frac{\{(x_1 − \bar{x})^2 + (x_2 − \bar{x})^2 + \cdots + (x_n − \bar{x})^2\}}{n}\end{align}
(見切れる場合は横へスクロール)
分散を \(s^2\)、データの値を \(x\)、平均値を \(\bar{x}\) とすると、
\begin{align}s^2 = \overline{x^2} − (\bar{x})^2\end{align}
つまり、偏差の \(2\) 乗の総和をデータの総数で割る(公式①)、または、(データの \(2\) 乗の平均値) から (データの平均値の \(2\) 乗) を引く(公式②)ことで求められます。
 分散とは?公式や求め方、計算問題をわかりやすく解説!
分散とは?公式や求め方、計算問題をわかりやすく解説!
標準偏差 \(s\)
標準偏差も、データの散らばり度合いやばらつきを表す値です。
標準偏差は分散の正の平方根であり、データと単位がそろった指標であるため、よく用いられます。
標準偏差を \(s\)、データの総数を \(n\)、それぞれのデータの値を \(x_1\), \(x_2\), \(\cdots\), \(x_n\)、平均値を \(\bar{x}\) とすると、
\begin{align}s = \displaystyle \sqrt{\frac{\{(x_1 − \bar{x})^2 + (x_2 − \bar{x})^2 + \cdots + (x_n − \bar{x})^2\}}{n}}\end{align}
(見切れる場合は横へスクロール)
 標準偏差とは?意味や求め方、計算問題をわかりやすく解説!
標準偏差とは?意味や求め方、計算問題をわかりやすく解説!
2 変量データの比較
ある集団の身長と体重、あるクラスの英語と数学のテスト結果など、同じ対象に対して \(2\) つのデータをとってそれらの関連性を調べたいことがあります。
このようなデータセットを「\(2\) 変量データ」といいます。
散布図と相関関係
散布図とは、縦軸・横軸に各データの値をとったグラフで、\(2\) 変量データの関連性を可視化できます。
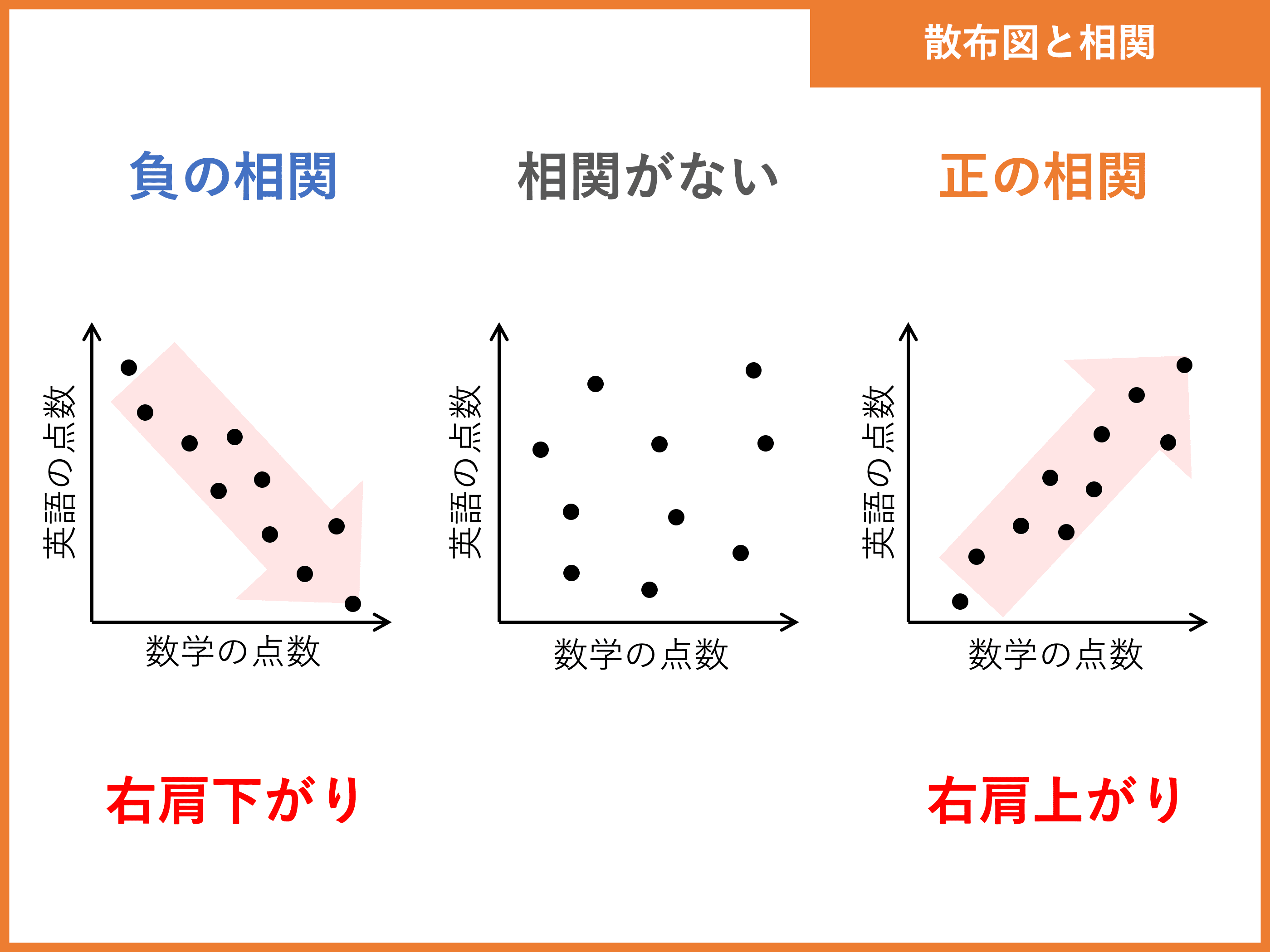
散布図が右肩上がりの直線性を示すことを「正の相関」、右肩下がりの直線性を示すことを「負の相関」といいます。
直線性が特に見られない場合は、「ほとんど相関がない」と表現します。
共分散 \(s_{xy}\)
共分散とは、\(2\) 変量データの相関の有無を示す数値であり、\(2\) つのデータの偏差の積の平均で定義されます。
共分散を \(s_{xy}\)、\(2\) 組の対応するデータの値を \(x_1\), \(x_2\), \(\cdots\), \(x_n\) と \(y_1\), \(y_2\), \(\cdots\), \(y_n\) とし、それぞれの平均値を \(\bar{x}\), \(\bar{y}\) とすると、
\begin{align}s_{xy} = \displaystyle \frac{1}{n} \{(x_1 − \bar{x})(y_1 − \bar{y}) + (x_2 − \bar{x})(y_2 − \bar{y}) + \cdots + (x_n − \bar{x})(y_n − \bar{y})\}\end{align}
(見切れる場合は横へスクロール)
また、共分散は (積の平均) − (平均の積) でも求められます。
共分散を \(s_{xy}\)、\(2\) 組の対応するデータの値を \(x\), \(y\) とし、それぞれの平均値を \(\bar{x}\), \(\bar{y}\)、それぞれの積の平均値を \(\overline{xy}\) とすると、
\begin{align}s_{xy} = \overline{xy} − \bar{x} \cdot \bar{y}\end{align}
共分散が正の場合は「正の相関」が、共分散が負の場合は「負の相関」があることを示唆します。
 共分散とは?意味や公式、求め方と計算問題、相関係数との違い
共分散とは?意味や公式、求め方と計算問題、相関係数との違い
相関係数 \(r\)
相関係数とは、\(2\) 変量データの相関の強さを示す数値です。
相関係数は \(−1 \leq r \leq 1\) の値をとり、\(1\) に近いほど「正の相関」が、\(−1\) に近いほど「負の相関」が強いことを意味します。
\(2\) 変量データ \((x, y)\) の相関係数 \(r\) は、以下の式で表される。
\begin{align}\displaystyle r &= \frac{s_{xy}}{s_x \cdot s_y} \\&= \frac{\frac{1}{n} \sum_{i = 1}^n (x_i − \bar{x})(y_i − \bar{y})}{\sqrt{\frac{1}{n} \sum_{i = 1}^n (x_i − \bar{x})^2} \sqrt{\frac{1}{n} \sum_{i = 1}^n (y_i − \bar{y})^2}}\end{align}
(見切れる場合は横へスクロール)
\(s_{xy}\) : \(x, y\) の共分散
\(s_x\) : \(x\) の標準偏差
\(s_y\) : \(y\) の標準偏差
\(n\) : データの総数
\(x_i, y_i\) : \(i\) 番目の \(x, y\) の値
\(\bar{x}, \bar{y}\) : \(x, y\) の平均値
 相関係数 r とは?公式と求め方、相関の強さの目安を解説!
相関係数 r とは?公式と求め方、相関の強さの目安を解説!
裏ワザ① 重要公式の覚え方
データの分析の公式は、数式のまま覚えようとするととても複雑に感じます。
各公式の関係性とつながりを意識すると、公式を覚えやすくなりますよ。
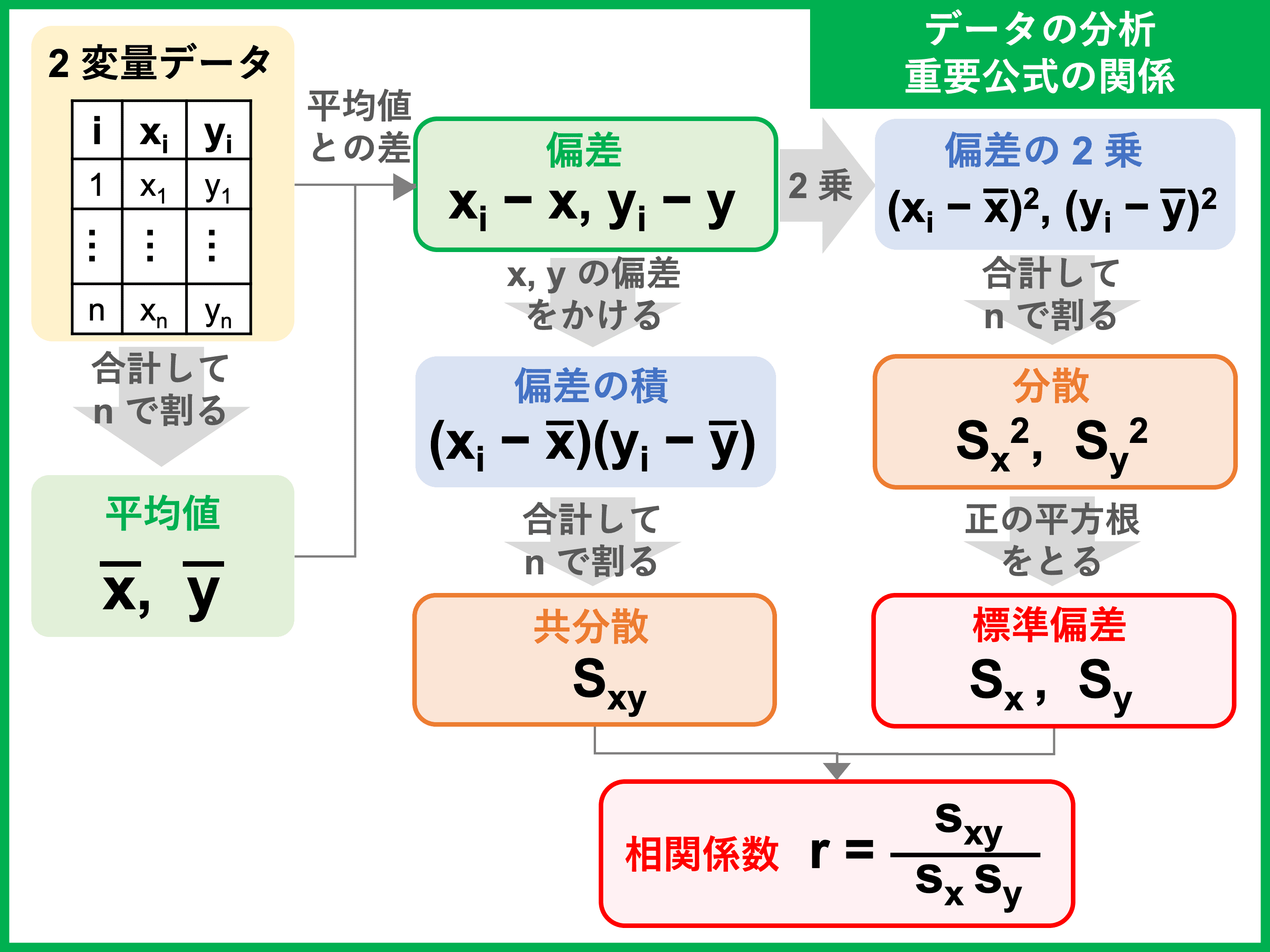
裏ワザ② 平均値〜相関係数までの求め方
定期テストや共通テスト等でデータの分析が出題された場合、二変量データの平均値、分散、標準偏差、共分散、相関係数などの統計量を求める問題がほぼ確実に含まれます。
その際、個々の統計量を次のような表を使って計算していくのがオススメです。
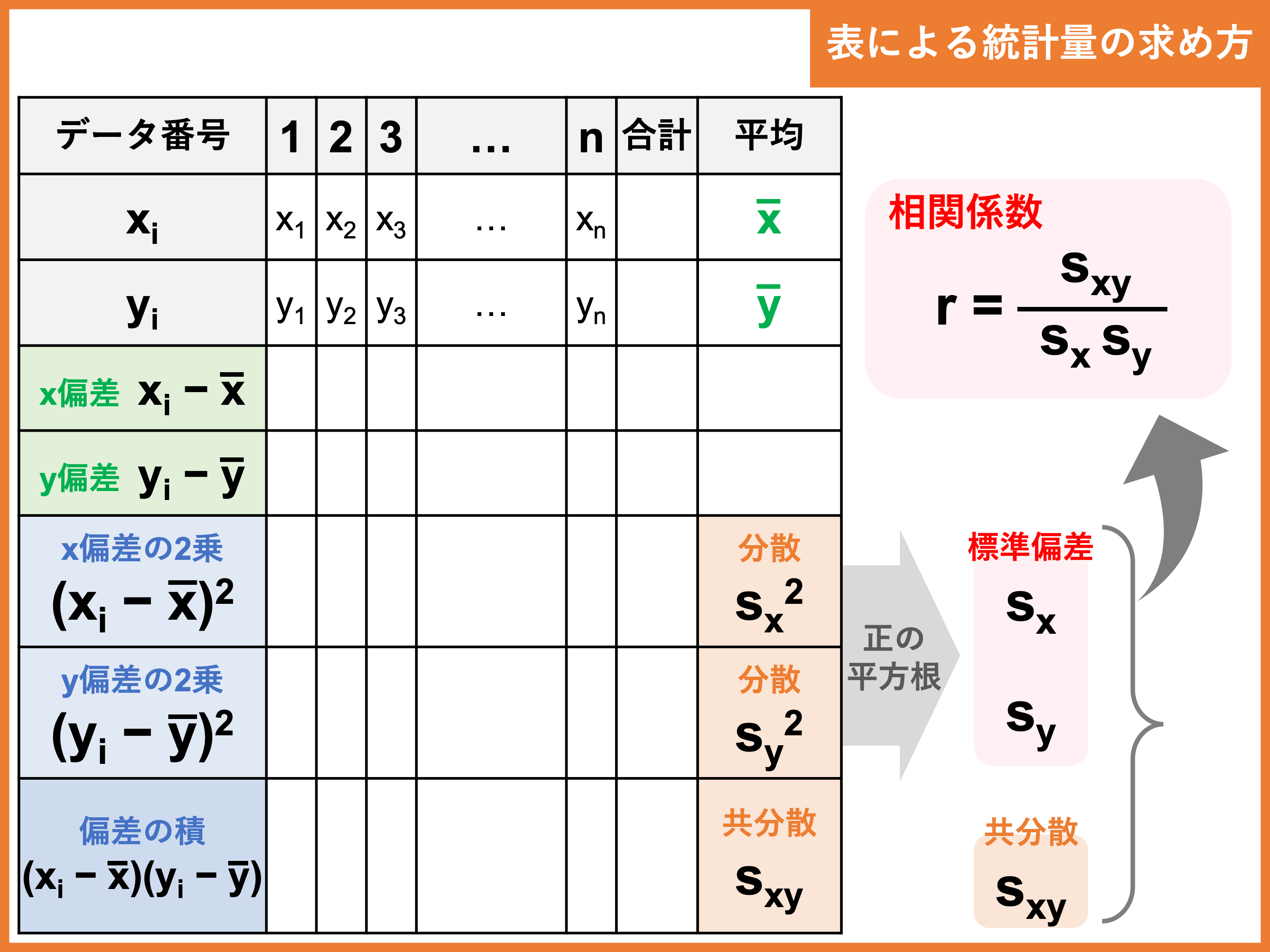
書き漏らしによる計算ミスもグッと減りますし、各統計量のつながりも整理しやすくなります。
特に、「偏差」は主要な統計量すべてに関係するので、設問になくてもしっかり書き出しておきましょう!
以上がデータの分析の公式一覧でした!
データの分析は、共通テスト(旧・センター試験)でも当然出題されます。
公式とそれぞれの使いどころさえ押さえていれば特別な発想は必要なく、点数を稼ぎやすい単元といえます。
関連記事も確認しながら、ぜひデータの分析をマスターしてくださいね!
摸試の直前に見ました。出たか出てないかでいえばよく分からなかったのですがためになったかなってないかでいえばなった気もするしなってない気もします。でもなってるんかな【藁】
この度はコメントいただきありがとうございます。
今後ともどうぞ当サイトをよろしくお願いいたします。
入試前に見てるぜイェーイ
この度はコメントいただきありがとうございます。
ふだんから使い慣れた教材等と併用して、当サイト記事をご活用ください。
今後ともどうぞ当サイトをよろしくお願いいたします。
模試のたびに見てる
でも分散は偏差の二乗平均ではなくないか
この度はコメントを頂きありがとうございます。
ご指摘のとおり、不適切な表現がありましたので該当部分を修正いたしました。
このようにご指摘いただけるととても助かります。
今後ともどうぞ当サイトをよろしくお願いいたします。